先介绍浏览器加载一个HTML文件需要做哪些事,帮助我们理解为什么我们需要虚拟DOM。webkit引擎的处理流程,一图胜千言:
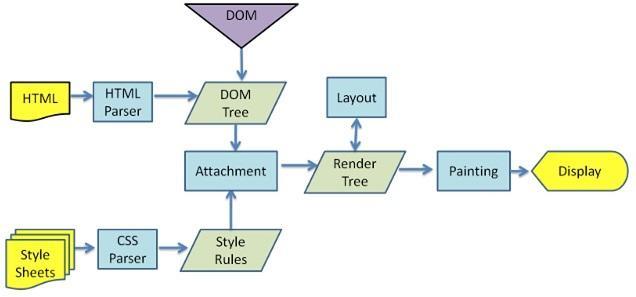
所有浏览器的引擎工作流程都差不多,如上图大致分5步:创建DOM tree –> 创建Style Rules -> 构建Render tree -> 布局Layout –> 绘制Painting
第一步,用HTML分析器,分析HTML元素,构建一颗DOM树。
第二步:用CSS分析器,分析CSS文件和元素上的inline样式,生成页面的样式表。
第三步:将上面的DOM树和样式表,关联起来,构建一颗Render树。这一过程又称为Attachment。每个DOM节点都有attach方法,接受样式信息,返回一个render对象(又名renderer)。这些render对象最终会被构建成一颗Render树。
第四步:有了Render树后,浏览器开始布局,会为每个Render树上的节点确定一个在显示屏上出现的精确坐标值。
第五步:Render数有了,节点显示的位置坐标也有了,最后就是调用每个节点的paint方法,让它们显示出来。
当你用传统的源生api或jQuery去操作DOM时,浏览器会从构建DOM树开始从头到尾执行一遍流程。比如当你在一次操作时,需要更新10个DOM节点,理想状态是一次性构建完DOM树,再执行后续操作。但浏览器没这么智能,收到第一个更新DOM请求后,并不知道后续还有9次更新操作,因此会马上执行流程,最终执行10次流程。显然例如计算DOM节点的坐标值等都是白白浪费性能,可能这次计算完,紧接着的下一个DOM更新请求,这个节点的坐标值就变了,前面的一次计算是无用功。
即使计算机硬件一直在更新迭代,操作DOM的代价仍旧是昂贵的,频繁操作还是会出现页面卡顿,影响用户的体验。真实的DOM节点,哪怕一个最简单的div也包含着很多属性,可以打印出来直观感受一下:

虚拟DOM就是为了解决这个浏览器性能问题而被设计出来的。例如前面的例子,假如一次操作中有10次更新DOM的动作,虚拟DOM不会立即操作DOM,而是将这10次更新的diff内容保存到本地的一个js对象中,最终将这个js对象一次性attach到DOM树上,通知浏览器去执行绘制工作,这样可以避免大量的无谓的计算量。